INTRODUCTION
In clinical and epidemiological studies, biomarkers are associated with disease diagnosis and prognosis, the two major determining factors for managing a patient’s care. For this purpose, biomarkers can be used to divide patients into two groups, such as high-risk or low-risk groups, which have statistical and clinical advantages. A continuous variable may have clinical significance concerning the outcome, but its effects may be non-linear or non-monotonic [1]. Patient classification into two groups based on the presence of a biomarker may help to apply different care or procedures to each group. For example, it may be helpful to divide lung cancer patients into two groups based on tumor size and to apply radiotherapy or pneumonectomy to each group, to provide the most effective treatment. However, the method for choosing the actual cutoff is not straightforward and many possible approaches are available for such classification. A cutoff can be selected without using data, where a priori biological reasoning, a clinician’s experience, or published results are considered. Although, the choice of a cutoff based on the clinician’s experience may depend on his or her criteria, cutoffs may vary due to difference of subjects across previous studies [2-4]. Statistical methods based on data are also applicable for estimating new cutoff values.
There are two statistical approaches for determining a cutoff value: biomarker-oriented and outcome-oriented. The biomarker-oriented approach splits a continuous marker about some percentile or the mean of biomarker values. In contrast, the outcome-oriented approach selects the biomarker cutoff that takes into account the association between outcome and biomarker. The outcome-oriented approach is expected to provide a better cutoff value than the biomarker-oriented approach [5]. Even though the biomarker-oriented approach is a simple exploratory method, it may fail to select a cutoff related to outcome. The cutoff estimated by the outcome-oriented approach can be applied to predicting patient prognosis. This article describes several methods of statistical inference used to estimate and test cutoff values, with a focus on the outcome-oriented approach.
METHODS
Minimum P-value approach
A widespread, straightforward method is to select a cutoff value that corresponds to the most significant difference in the prognosis of an outcome between the two groups and one that provides the minimum P-value among all potential cutoffs. Cutoff values are determined from the entire range (minimum, maximum) for a biomarker or from a selected range, which excludes clinically non-relevant cutoff values. For example, in a data set with a size (n=10), a binary outcome (Y=0, 1), and a continuous biomarker (X), the data sets are examined to determine what cutoff value best separates the two groups. For each potential cutoff, c, the investigator draws a 2×2 table and then selects a cutoff value that maximizes the chi-square statistic, while equivalently minimizing the P-value (Pmin) (Table 1). However, with such a procedure, the problem of multiple testing arises. This means that the significance of the chosen cutoff value tends to be overestimated [6-10]. Adjustment approaches have been developed to resolve the increase in false positive error rate.
Adjustment methods to correct P-values
Bonferroni method
To protect from the increase of false positive error rate, a new P-value is obtained by multiplying the minimum P-value by the number of tests performed.
Pbon=Pmin×the number of tests performed
In the Table 1, the chi-square test is conducted for each c and the corrected P-value for the cutoff corresponding to Pmin, Pbon, equals Pmin×9. This method is relatively easy for calculating the corrected P-value and can be applied to any type of outcome. However, the method is conservative, and with more candidate cutoff values it becomes more difficult to reach statistical significance.
Miller and Siegmund method
The Miller and Siegmund method [11] selects the interval of a continuous biomarker, X, (X(ε), X(1-ε); 0<ε<0.5) which is symmetric in the tail areas. For example, with ε=0.1, the range of candidate cutoffs of X is selected as (10th percentile, 90th percentile). Among the potential cutoff values within the interval (X(ε), X(1-ε); 0<ε<0.5), the asymptotic distribution of the maximum chi-square statistic regarding binary outcome is derived and the formula for the P-value corresponding to the cutoff with the maximum chi-square statistic using this distribution is as follows:
where z is the 1 - p min 2
Lausen and Schumacher method 1
This approach [12] generalizes the Miller and Siegmund method so it can be extended to asymmetric ranges (X (ε1), X (ε2); 0<ε1<ε2<1) of candidate cutoff values for a biomarker. If the investigator excludes the lower 5% and the upper 10% of the biomarker data, the cutoff value is searched within the interval (5th percentile, 90th percentile). The P-value corresponding to the cutoff with Pmin is computed using the following formula:
This method has the advantage that it can be applied to data with ordinal outcome, continuous outcome and time to event outcome as well as binary outcome, but it has the same disadvantage as the Miller and Siegmund method concerning small data sets.
Lausen and Schumacher method 2
Lausen et al. [13] developed a formula for the P-value using an improved Bonferroni’s inequality and asymptotic method [14,15] when the number of candidate cutoff values is not very high (50 to 100). This method also considered the correlation between the test statistics for adjacent cutoff values. The equation is as follows:
where li is the number of observations which is less than or equal to ith candidate cutoff value (i=1,…,k-1). The value of the function of D is calculated with the following formula:
This formula can be also applied to binary outcome, ordinal outcome, continuous outcome and time to event outcome. We recommend to use the smaller of P-values of P(2)and P(3) [16].
Contal and O’Quigley method
This method provides a P-value that is derived from an asymptotic distribution of an adjusted statistic for the log-rank test to compare survival curves [17]. The equation is as follows:
where Lk is the log-rank statistic computed at the kth candidate cutoff value, and s is calculated with
1 ( k - 1 ) ∑ j = 1 k a j 2 1 - ∑ i = 1 j ( 1 k - i + 1 )
Woo et al. method
Competing risk is an event that either hinders the observation of the event of interest or modifies the chance that this event occurs. For example, after a bone marrow transplantation, when studying leukemia relapse, non-relapse death can be considered as a competing risk. With these types of data, a popular method to compare survival curves is Gray’s test [18]. Woo et al. [19] developed a P-value derived from the asymptotic distribution of the modified statistic (q’) for Gray’s test and the equation is shown below.
Gk is the Gray’s statistic calculated at the kth cutoff value and s is calculated with
1 k - 1 ∑ j = 1 k a ' j 2
Table 2 summarizes the types of outcomes and the various adjustment approaches for correcting P-values to prevent an increase in false positive error rates due to the multiple testing problem that occurs during the process of inference for biomarker cutoff value determination.
Software packages for the Miller and Siegmund method, the Lausen and Schumacher methods 1 and 2, and the Hothorn and Lausen method are available in the R package (R Foundation for Statistical Computing, Vienna, Austria) “maxstat”. Also, package “survMisc” in the R can be used for the Contal and O’Quigley method. Woo et al. method was implemented in a SAS macro (SAS Institute Inc., Cary, NC, USA), and code will be made available upon request.
APPLICATIONS
Leukocyte elastase and coronary artery disease
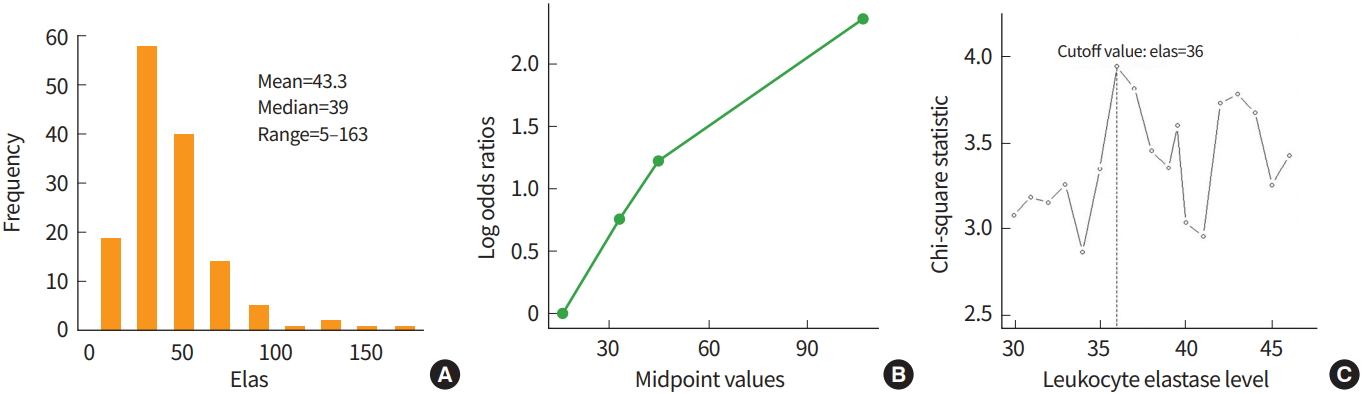
The data from 141 subjects were collected to investigate the clinical usefulness of leukocyte elastase in the diagnosis of coronary artery disease (CAD) [20]. The mean, median, and range of leukocyte elastase were 43.3, 39.0, and 5 to 163, respectively. To explore the possibility that a cutoff exists, the log-odds ratio for each quantile of leukocyte elastase data was examined. Fig. 1 graphically presented that a cutoff around the median value 39 may divide the subjects into two groups. Since the outcome, CAD, is a type of binary data, four methods to select a cutoff using a corrected P-value can be applied, and the results from each method are displayed in Table 3. The leukocyte elastase cutoff is estimated to be 36 from all methods. The minimum P-value approach provided a significant P-value of 0.0014, which does not correct for the false positive error rate increase. The corrected P-value from the Bonferroni method is the largest as expected, and the P-values resulting from the other methods, P(1), P(2), and P(3) were all significant. The results demonstrate that we can divide the subjects into two groups regarding CAD using a significant cutoff of 36 for leukocyte elastase.
Mean gene expression level and death in diffuse large B-cell lymphoma patients
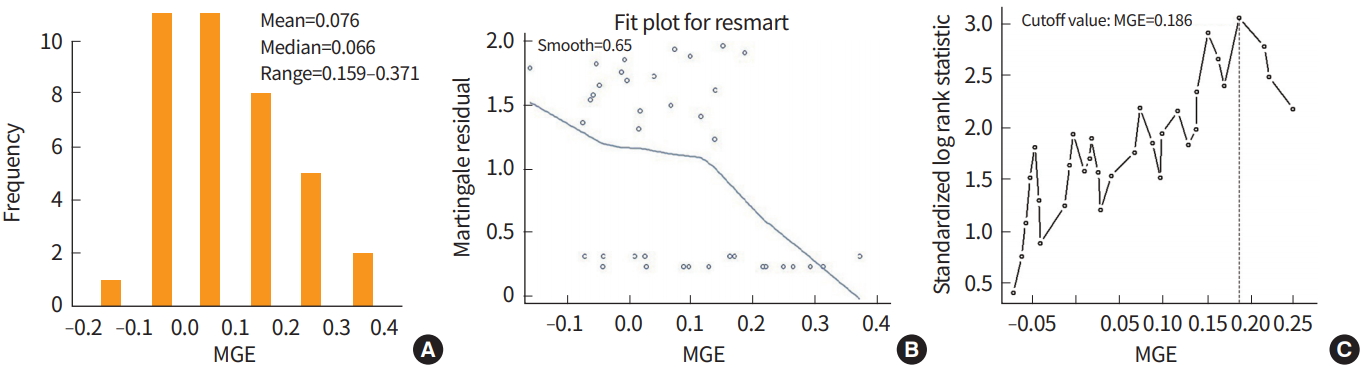
In data from 38 lymphoma patients (http://llmpp.nih.gov/lymphoma/data.shtml) [21], a cutoff value for mean gene expression (MGE) was estimated to classify the patients into low-risk or high-risk of death groups. Among 38 patients, 20 patients died and 18 patients were censored during the study period. The mean, median, and range for the MGE were 0.076, 0.066, and –0.159 to 0.371, respectively. Martingale residuals for survival model were examined to determine if there was a possible cutoff for MGE. The residual slope decreased rapidly after approximately 0.1 and the probability of death may be different between the two groups if classifying by an MGE cutoff of 0.1 (Fig. 2).
Because the outcome of this data is death, which is a time to event, we could determine an MGE cutoff for the prognosis of death in lymphoma patients using the Contal and O’Quigley method as well as the Bonferroni method, and the Lausen & Schmacher methods 1 and 2. From these methods, the estimated MGE cutoff value was the same at 0.186 and the P-values corresponding to this cutoff were all significant except for the Bonferroni method result (Table 4).
Tumor size and recurrence in lung cancer patients
The data from 758 lung cancer patients undergoing tumor removal from 1991 to 2005 were collected. The data consisted of tumor size (cm) as a biomarker for recurrence. In this data, death after surgery was treated as a competing risk event. Among 758 patients, 580 patients had recurrences, 65 patients died without a recurrence, and 113 patients were censored. The distribution of tumor size was skewed to the right, with a median, mean and range of 3.0, 3.3, and 0.0 to 19.0, respectively. A Martingale residual plot showed a non- linear pattern of association between tumor size and time to recur and demonstrated a possible cutoff for tumor size around 3.0 cm. The rightmost plot in Fig. 3 shows that the standardized Gray’s statistic is maximized at a tumor size of 2.7 cm. With this cutoff value, the P-value was <0.0001 when applying the Woo et al. method.
CONCLUSION
Biomarkers, which can be measured as continuous or categorical data types, play a role as risk factors or predictors of clinical outcomes. In clinical practice, biomarker data, which is usually a continuous measurement, is often divided into two categories based on an optimal cutoff value. This kind of categorization makes it easier to interpret the effects of a biomarker on the outcome via an odds ratio or risk ratio. It also helps clinicians by providing objective criteria in the selection of treatment options. In this article, we focused on the dichotomization of continuous biomarkers and presented several methods to resolve the problem associated with the increase in false positive error rate, which occurs during multiple testing. We summarized the methods according to the type of outcome and presented some of their applications.
Miller and Siegmund method [11] is relatively easy to use, but it is appropriate to use only for binary outcome. For ordinal, continuous outcomes in addition to binary outcomes, Lausen and Schumacher methods [12,13] can be applied. And, when the outcome of interest is time to event, Lausen and Schumacher methods [12,13] and Contal and O’Quigley method [17] can be applied where competing risk is not taken into account. Contal and O’Quigley method [17] has the advantage of having a higher power and lower bias than Lausen and Schumacher methods [12,13] when there is a high proportion of censoring in the data. Woo et al. method [19] can be used for time to event outcome considering competing risk event and this method is powerful under no censoring. When there is a high proportion of censoring in outcome with competing risk event, an empirical P-value based on a lot of permuted samples is closer to the nominal level than the approximate test.
There are possibilities associated with the loss of information from the data, including a decrease in the power for detecting statistical significance and the biased estimation in the process of categorizing a continuous biomarker. Therefore, the cutoff value should be estimated after fully examining the feasibility of categorization using both clinical and data-driven factors [22,23].